08/24/2023
Enterprise
Will Enterprise AI Models Be “Winner Take All?”
A Cambrian explosion of models creates a broad set of opportunities in AI Infrastructure
Over the past decade, we at Lightspeed have had a front row seat to the incredible innovations in AI/ML thanks to the amazing founders we’ve had the privilege to partner with. We’ve been working with their companies, the platforms they’ve built, and the customers they serve, to better understand how enterprises are thinking through GenAI. Specifically, we have investigated the foundation model ecosystem with questions like, “Will the best performing model have winner-take-all dynamics?” and, “Will enterprise use cases all default to calling, say, OpenAI APIs, or will actual usage be more diverse?” The answers will determine the future growth of this ecosystem, and in what direction energy, talent, and dollars will flow.
Categorizing the Model Ecosystem
Based on our learnings, our belief is that there’s a Cambrian explosion of models coming in AI. Developers and enterprises will pick models best suited for the “job to be done,” even though the usage at exploratory stages might look a lot more concentrated. A likely path for enterprise adoption could be the use of big models for exploration, gradually moving to smaller specialized (tuned + distilled) models for production as they learn more about their use case. The following visual helps outline how we see the Foundation Model ecosystem evolving.
The AI model landscape can be divided into 3 primary, though somewhat overlapping, buckets:
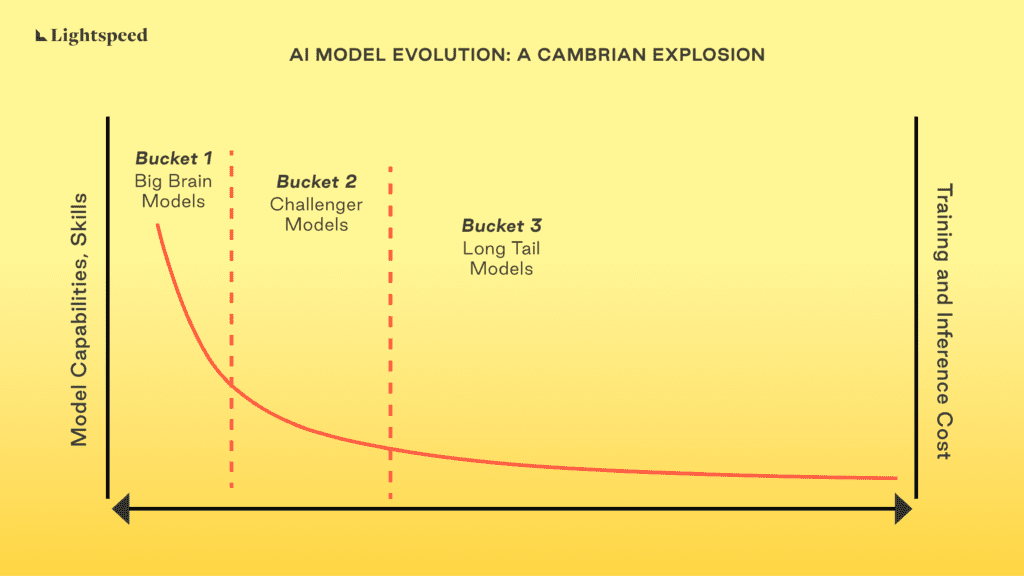
Bucket 1: “Big Brain”
These are the best of the best, the leading edge of models. This is where the exciting magical demos that have captivated us all are coming from. They are often the default starting point for developers when trying to explore the limits of what AI can do for their apps. These models are expensive to train, and complex to maintain and scale. But the same model could take the LSAT, the MCAT, write your high school essay, and engage with you as a chat-bot-friend. These models are where developers are currently running experiments and evaluating AI usage within enterprise applications.
But, they are expensive to use, inference latency is high, and can be overkill for well-defined constrained use cases. A second issue is that these models are generalists that can be less accurate on specialized tasks. (For instance, see meta studies such as this one from Cornell.) Lastly, today, in almost every case, they are also black boxes that can present privacy and security challenges for enterprises who are grappling with how to utilize these without giving away the farm (their data!). OpenAI, Anthropic, Cohere are examples of companies in this bucket.
Bucket 2: “Challenger”
These are also high-capability models, with skills and abilities just below the most cutting edge. Models such as Llama 2 and Falcon are the best representations in this category. They are often as good as some of the Gen “N-1” or “N-2” models from the companies building the Bucket 1 models. By some benchmarks, Llama2, for instance, is as good as GPT-3.5-turbo. Tuning these models on enterprise data can bring their abilities to be as good as Bucket 1 models on specific tasks.
Many of these models are open source (or close enough) and once released have led to immediate improvements and optimizations by the open source community.
Bucket 3: “Long Tail”
These are “expert” models. They are built to serve a narrow purpose, like classifying documents, identifying a specific property in an image or video, identifying patterns in business data, etc. These are nimble, inexpensive to train and use, and can be run in data centers or on the edge.
A quick look at Hugging Face is enough to get a sense for how vast this ecosystem already is and will grow to be in the future, thanks to the breadth of use cases it serves!
Matching Use Cases to Models
While early, we’ve seen some of the leading development teams and enterprises already thinking about the ecosystem in this nuanced way. There’s a desire to match the use to the best possible model. Perhaps even use multiple models to serve a more complex use case.
The factors used in evaluating which model/s to use often include the following:
- Data privacy and compliance requirements, which impact whether the model needs to run in enterprise infrastructure, or if data can be sent to an external hosted inference endpoint.
- Whether the ability to fine tune a model is critical or strongly desired for this use case.
- What level of inference ‘performance’ is desired (latency, precision, expense, etc.).
The actual list is often much longer than just the above and is reflective of the tremendous diversity in use cases that developers would like to use AI for.
Where are the opportunities?
There are several implications of this emerging ecosystem:
- Evaluation Frameworks: Enterprises will need access to tooling and expertise that can help evaluate which model to use for which use case. Developers will need to decide how best to evaluate the suitability of a specific model for the ‘job to be done.’ The evaluation would need to be multi-factor and include not just the performance of the model, but also the cost, the level of control that can be exercised etc.
- Running and Maintaining Models: Platforms to help enterprises train, fine tune, and run models, especially the Bucket 3, long tail models, will emerge. Traditionally, these have broadly been referred to as ML Ops platforms, we expect that definition will expand to include generative AI as well. Platforms such as Databricks, Weights and Biases, Tecton and others are rapidly building towards this.
- Augmentation Systems: Models, particularly hosted LLMs, need retrieval augmented generation to deliver superior results. This requires a secondary set of decisions to be made, including:
- Data and meta-data ingestion: How to connect to structured and unstructured enterprise data sources and then ingesting both data, as well as meta data on things such as access policies.
- Generating and storing embeddings: Which model to use to generate embeddings for the data. And then how to store them: Which vector database to use, specifically based on performance, scale and functionality desired?
Opportunities exist here to build enterprise class RAG platforms which can take away the complexity associated with selecting and stitching together these platforms:
- Operational Tooling: Enterprise IT will need to build guardrails for engineering teams, manage costs, etc.; all the tasks that they handle today for software development need to be expanded now to include AI usage. Areas of interest for IT include:
- Observability: How are the models doing in production? Is their performance improving/degrading with time? Are there usage patterns that might impact the choice of model in future versions of the application?
- Security: How to keep AI native applications secure. Are these applications vulnerable to a new class of attack vectors that need new platforms?
- Compliance: We expect AI native applications and usage of LLM will need to be compliant with frameworks that relevant governing bodies are already beginning to work on. That’s in addition to the existing compliance regimes around privacy, security, consumer protection, fairness etc. Enterprises will need platforms that help them stay compliant, run audits, generate proof of compliance and associated tasks.
- Data: Platforms to help understand the data assets an enterprise has, and how to use those assets to extract the maximal value from new(er) AI models, will see rapid adoption. As one of the largest software companies on the planet once said to us, “our data is our moat, our core IP, our competitive advantage.” Monetizing this data using AI, in a way that drives additional “differentiation without diluting defensibility” will be key. Platforms such as Snorkel play a critical role in this.
This is an amazing time to be building platforms in AI infrastructure. Adoption of AI will continue to transform entire industries, but it will require supporting infrastructure, middleware, security, observability, and operations platforms to enable every enterprise on the planet to adopt this powerful technology. If you are building to make this vision become a reality, we’d love to speak with you!
Authors



