In February 2020, I attended my last conference before the pandemic broke out at the Computer History Museum in Mountain View, California. There, Andrej Karpathy, founding member of OpenAI and former Director of AI Tesla, spoke about a fascinating idea he had coined a few years earlier called Software 2.0.
In traditional Software 1.0, code is hand-engineered, made up of thousands or millions of explicit instructions, written manually by human software developers. A large and diverse apparatus of programming languages, integrated development environments (IDEs), and other tools has emerged to cater to this method of development. On the other hand, in Software 2.0 the “code” is encapsulated within the many parameters of a large neural network. We specify a goal or task, provide the model with some examples as training data, and the AI finds its own solution to the problem. Software 2.0 is a paradigm shift in how software is built.
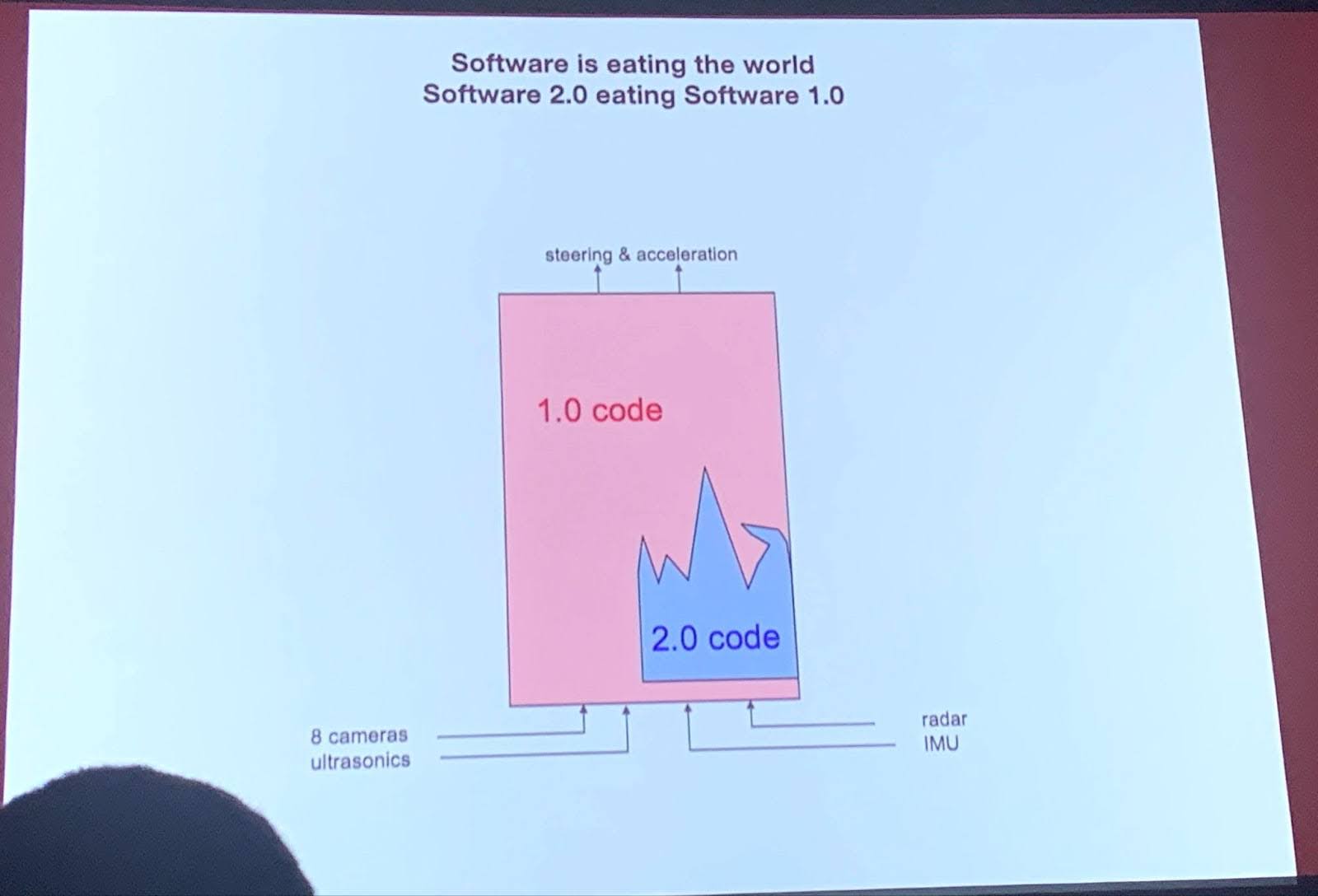
While exciting, Software 2.0 faces a number of roadblocks. With standard software, an engineer can change a single line of code – a small, atomic change to the overall program. Large language models (LLMs), in contrast, are difficult to precisely edit, as they have billions of parameters that interact in complex ways, lending them “black box” reputation. These peculiarities make LLMs difficult to debug, taking substantially more effort than traditional software programs, and challenging to fix in production, requiring costly downtime to make any modifications.
LLMs have traditionally been “programmed” by either training or prompt engineering, both of which have meaningful drawbacks:
- Training is resource expensive in terms of compute, data, and time while also being fundamentally coarse in nature — every new training example potentially affects the entire model.
- Prompt engineering, while powerful and intuitive, quickly hits diminishing returns and is inherently a trial and error process that is difficult to rigorously systematize.
However, there is a third way. Recent research results from major AI labs suggest that it is possible to introspect and “map” the brains of large language models, yielding insights into their thoughts and the “why” behind their behavior. This enables engineers to make surgical modifications to models’ behavior without requiring further training, similar to what software engineers do today in Software 1.0. This rapidly emerging field is called mechanistic interpretability, and we believe it will become an essential building block for responsible AI adoption and deployment.
Goodfire is building the IDE for Software 2.0, unlocking the ability to explore, debug, and edit large language models, bringing us closer to safe and reliable AI. CEO Eric Ho previously co-founded RippleMatch, an applied AI startup, and is a savvy technology leader, skilled across product, engineering, and go-to-market. Chief Scientist Tom McGrath was previously a Senior Research Scientist at Google DeepMind and founded their interpretability team. CTO Dan Balsam was previously founding engineer and Head of AI at RippleMatch, where he built out the core engineering organization and deployed LLMs in production. The team is also advised by Nick Cammarata, a former Thiel Fellow and key member of the original team at OpenAI that created the field of mechanistic interpretability.

Goodfire is a cutting edge applied research lab doing foundational research and building innovative products for Software 2.0. Their mission: to advance humanity’s understanding of and ability to steer advanced AI models. Goodfire’s initial product will allow engineers to:
- Isolate and label relevant concepts within the brain of a model
- Visualize those concepts at various layers of abstraction and hierarchy
- Edit the model in a surgical fashion, precisely and efficiently modifying the model’s downstream behavior
Today, Goodfire is laying down the fundamental primitives of interpretability tooling. Over time, we expect a wide array of interpretability use cases to emerge across retrieval-augmented generation (RAG), prompt tuning, model auditing, data verification, and more. As governments increasingly push regulation mandating explainable AI systems, enterprises will need to provide clear rationales for model behavior. In the not-too-distant future, we’ll look back and wonder how we ever lived in a world where we didn’t understand these models.
Goodfire is building critical infrastructure for the AI ecosystem — AI models that can interpret other models and an interface that can unlock value from these models. Goodfire has the opportunity to pioneer a new piece of the AI stack, productizing these tools in an accessible way for non-researchers and enterprises deploying AI in mission critical settings. We at Lightspeed are thrilled to lead their $7M seed round.
Goodfire is hiring a high-caliber team of interpretability researchers and engineers to advance humanity’s understanding of AI. Join them on their mission here.
Authors



