
You may have seen a paper out of Apple last month with the title, “The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity”, which caused a bit of a stir. The paper purported to show that:
- The accuracy of reasoning models collapses beyond a certain level of problem complexity.
- The self-reflection and self-correction mechanism of reasoning models are insufficient for general problem-solving.
- Reasoning models paradoxically reduce their “thinking” effort when encountering hard or complex problems.
The implication would be that these reasoning models have critical weaknesses, which will prevent them from scaling to the most complex, longest problems. If true, this would cap the potential gains of the current reinforcement learning-based post-training paradigm.
However, shortly after publication, numerous critiques surfaced that brought into question the paper’s methodology, which I’ll quickly outline below. Suffice it to say, the Apple researchers overreached in the extent of their claims and suggestions. The paper does raise interesting fundamental questions about reasoning models but does not strictly prove the core claims.
What did the Apple paper show?
The researchers set up a number of logic puzzles and varied the degree of complexity up and down for each task, testing model accuracy and compute used (measured in “thinking tokens” outputted). They compared multiple reasoning models (Claude, o3, DeepSeek) along with their non-thinking/reasoning variants.
The accuracy results showed:
- Reasoning models match or outperform non-thinking models for problems up to medium complexity.
- For high-complexity problems, performance for both variants collapses to zero.
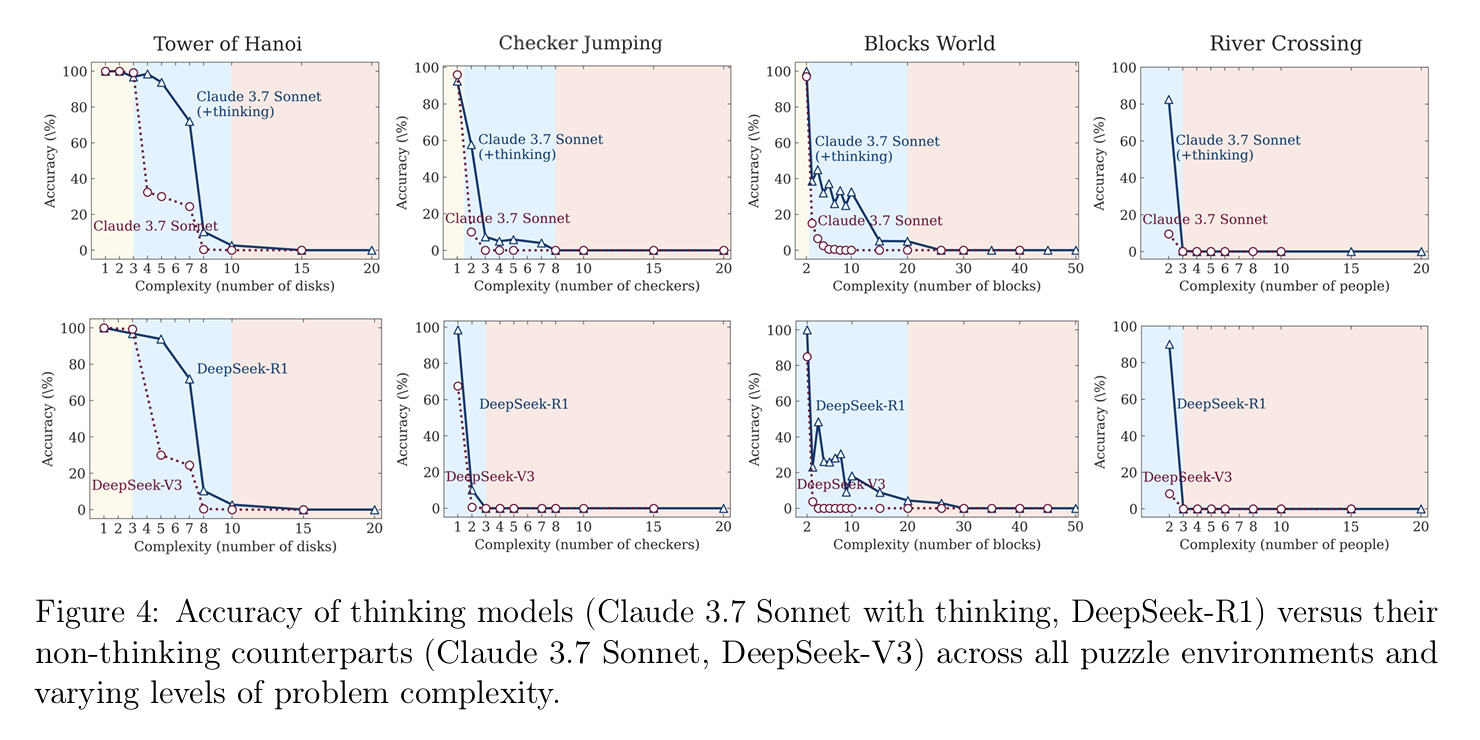
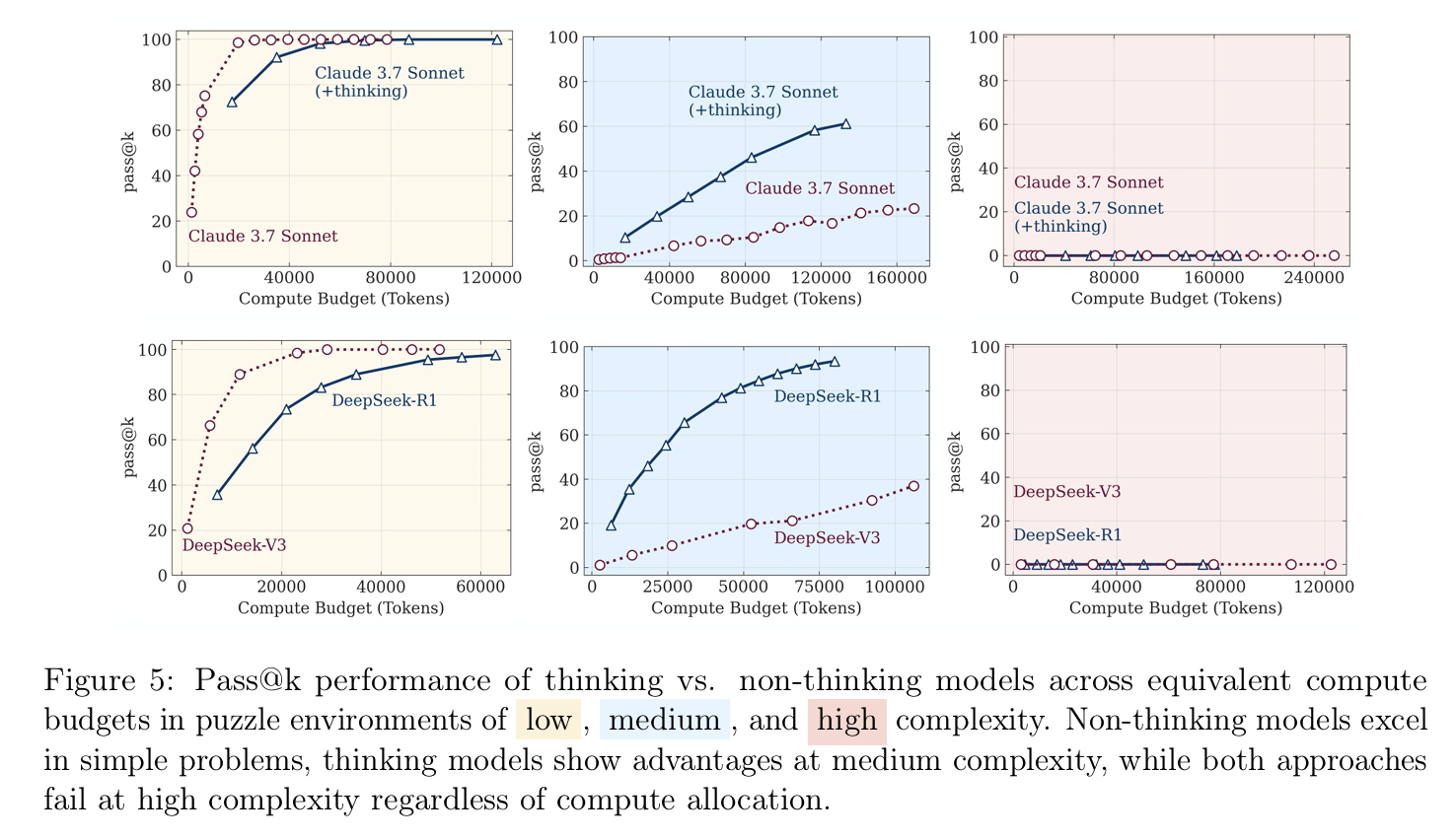
On compute/thinking time:
- Thinking compute increases through medium complexity problems.
- After reaching a certain maximum, thinking compute starts to plateau or even fall off with the complexity of the problem.
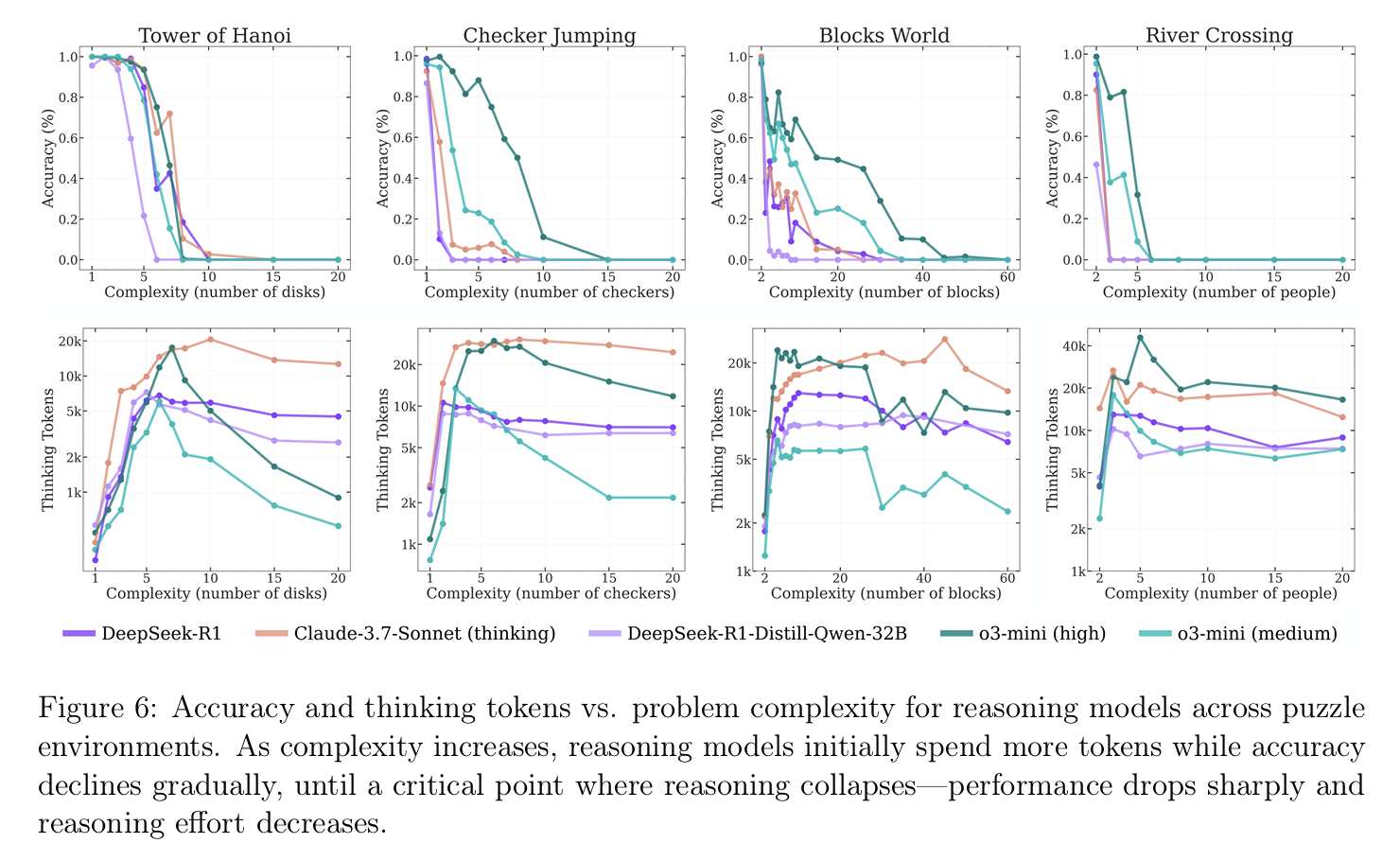
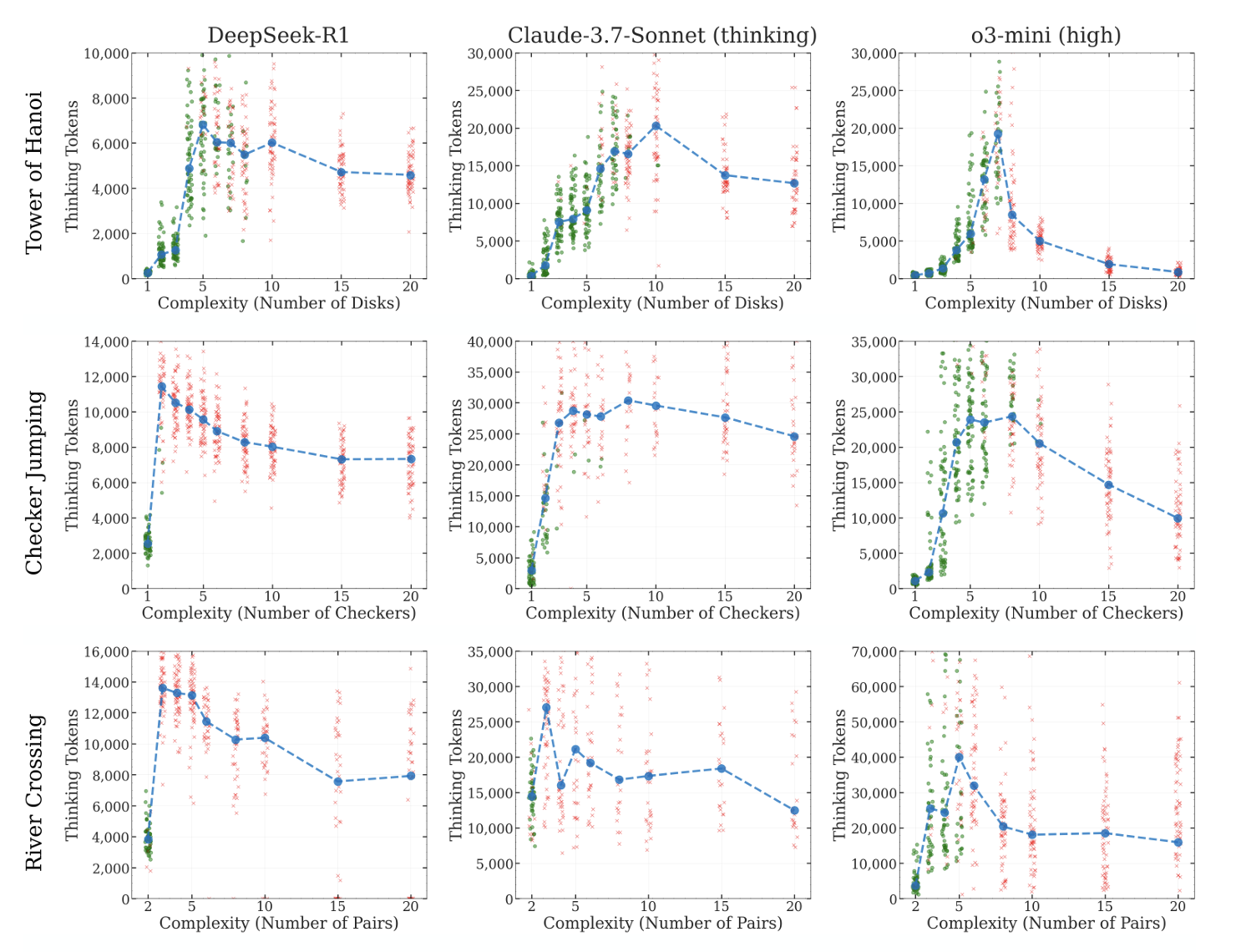
Taken at face value, the above evidence suggests these models fail at general problem-solving, which requires adapting to task difficulty on the fly. The models fail to do this, and are in some sense, maladaptive to the puzzles posed in these experiments.
Where did the Apple paper miss the mark?
Reasoning models are foundation models that have been post-trained to exhibit certain desired behaviors. Therefore, any test of those models is arguably more a test of the post-trained behavior than a test of the model’s fundamental capabilities.
In particular, these models are usually post-trained to avoid generating extremely long responses:
- While the model retains some ability to adjust the length of its answers up and down, it will avoid responses exceeding a certain length, even if the question or task demands it.
- Therefore, when tested on a question requiring an answer longer than it was post-trained to provide, the model will tend to cut its answer short on purpose (“The pattern continues, but to avoid making this too long, I’ll stop here”). This doesn’t prove that it couldn’t answer the question, only that it chooses not to, due to how it’s been trained.
- Because most frontier reasoning models are closed models, only the model companies themselves can increase this length limit, making it difficult to independently test in a robust way.
What this means in practice is that tasks that require extremely long token streams to tackle are poor tests of model ability, as the model simply can’t output that many tokens. For such problems, we simply don’t know how strong the model is under the hood.
The author’s definition of “complexity” requires longer answers, which is why the models ultimately perform so poorly on high-complexity tasks. Again, this is a flawed way to assess their capabilities because they literally cannot output such long responses given the way they’ve been trained.
Implications
The key question of whether these reasoning models are in fact doing something within the mind of the model that we’d recognize as “reasoning” remains open:
- Today, we refer to such models as reasoning models because the string of tokens they emit mimics what we think it sounds like for a human to reason through a problem.
- When Claude or ChatGPT says it’s “thinking,” that merely means that the model is currently outputting thinking tokens, and the length of time it thinks corresponds to the length of that sequence of tokens. When the thinking tokens are done, it transitions to “answer” tokens.
- But that is not the same thing as the model actually “reasoning” within the weights and activations of the model. We don’t actually know if that’s happening, and it very well may not be.
To the extent that true reasoning lies within the model (in its weights and activations, latent space, etc.) rather than outside of it (in its tokens), tests like those in the Apple paper will always be incomplete evaluations of model capabilities. Reasoning is challenging to test based on outputs alone, and therefore, programmatic evaluation must be carefully designed to be informative.
Dive deeper
- The Original Research: Apple’s Illusion of Thinking Paper
- Community Response and Critiques: Methodology concerns, Alternative analysis
- Additional Context: Related reasoning research, Video guide to reasoning models
The content here should not be viewed as investment advice, nor does it constitute an offer to sell, or a solicitation of an offer to buy, any securities. The views expressed here are those of the individual Lightspeed Management Company, L.L.C. (“Lightspeed”) personnel and are not the views of Lightspeed or its affiliates.
Authors



