


EXECUTIVE SUMMARY
If you were not paying attention, the AI boom seems like it came out of nowhere, arriving at a stroke with the release of ChatGPT in November 2022. In reality, it’s been building for years through the accumulation of discoveries in basic research. Some of these led directly to the creation of pacesetting companies, while others established the foundation for entirely new ecosystems of innovation. Many did both.
At Lightspeed, we’ve been close observers of AI research over the last decade. We’ve also often been active participants in helping leading researchers turn their ideas into groundbreaking startups. We were early backers of Mistral, SKILD and Snorkel, all of which germinated from fundamental discoveries about AI technology. The breadth of our portfolio in this area reflects the deep expertise Lightspeed investors and advisors have at recognizing and cultivating the new discoveries in basic AI research that will lead to the next generation of breakout technology companies.
In this post we identify the most influential AI research papers of the past 15 years. We also trace how they reverberate in the startup world today, in the form of scientists who’ve become founders and institutions that have turned into hubs of the new AI ecosystem. Through this lens, we observe that there have been four main research waves that have built on each other and propelled AI to its current prominence:
MODEL ARCHITECTURE IMPROVEMENTS
Since the 2010s, advancements in AI model architecture have driven significant breakthroughs and startup innovation. These include AlexNet’s 2012 work on deep convolutional neural networks and the acclaimed paper Attention Is All You Need, which revolutionized natural language processing.
DEVELOPER PRODUCTIVITY GAINS
The past decade has seen significant advancements in tools and frameworks that have markedly improved developer productivity, which is essential for startup growth. Milestones include the introduction of TensorFlow (and others, like PyTorch, in 2015), the HuggingFace Transformers library, introduced in 2018, and Meta’s open-sourcing of the Llama models in 2023.
TASK PERFORMANCE
Increasing public interest in AI models has been driven by their consumer, developer, and enterprise applications for task execution, sparking additional research focus. Several different papers released in the past 10 years have revolutionized the efficiency and variety of task executions performed by AI: on training deep neural networks for complex task execution, joint learning for alignment and translation which led to reduced training complexity, a breakthrough in unsupervised learning which led to improved task performance without any fine-tuning, and the use of retrieval augmented generation (RAG) and external data stores for knowledge-intensive tasks
COMPUTE OPTIMIZATION
In the 2010s, new optimization techniques like dropout and batch normalization improved model performance and stability. In 2020, OpenAI’s landmark paper highlighted how model performance scales predictably with increased computational resources. This was followed in 2022 by DeepMind, which demonstrated the importance of balancing model size and training duration for optimal performance.
The rest of the post explores the broad currents and specific discoveries that underlie AI technology today—providing a better understanding of how we got where we are, and making it possible to anticipate where the most dynamic technology in generations is headed next.
AI Research Family Tree
PAPERS
EARLY BREAKTHROUGHS:
Early papers laid the groundwork for today’s AI ecosystem by introducing the frameworks, models, and methodologies that have become foundational to startup development and subsequent research. Frameworks like Transformers, GPT, Tensorflow, Bert, and others in these papers have introduced new architecture for natural language processing, training language models, and fine-tuning model development.
-
ImageNet Classification with Deep Convolutional Neural Networks (2012), Geoffrey Hinton, Ilya Sutskever, Alex Krizhevsky
Often referred to as AlexNet (due to author Alex Krizhevsky), this paper was a landmark achievement in the field of deep learning. It demonstrated that a deep convolutional neural network (CNN) with five convolutional layers achieved significantly better results than previous methods on the ImageNet dataset, dispelling skepticism and proving the viability of deep learning architectures for complex tasks like image classification.
The paper also highlighted the importance of leveraging GPUs (Graphics Processing Units) for training deep CNNs. GPUs are much faster at handling the parallel computations involved in training, making large-scale training feasible.
-
Deep Residual Learning for Image Recognition (2015), Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
Prior to this paper, training deep CNNs suffered from a degradation problem. As networks got deeper, accuracy would plateau or even decrease. The paper introduced the concept of residual learning, reformulating the layers in a CNN to learn residual functions that modify the input rather than trying to learn the entire mapping from scratch, allowing networks to learn identity mappings more easily and enabling much deeper architectures.
Residual connections allowed researchers to train significantly deeper CNNs than previously possible. Residual connections are now a fundamental building block in most modern model architectures. This includes highly successful models like ResNet (the model from the original paper itself), Inception, and DenseNet.
-
Neural Machine Translation by Jointly Learning to Align and Translate (2016), Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio
Traditional neural machine translation (NMT) models often struggled with accurately aligning elements between the source and target sentences, leading to issues like missing information or incorrect word order in translated text. This paper introduced a new architecture where the model learns to align and translate jointly, allowing it to better capture the relationships between words and phrases in the source and target languages. The joint learning approach helps models produce more accurate and fluent translations, and can simplify the training process compared to separate alignment and translation models.
-
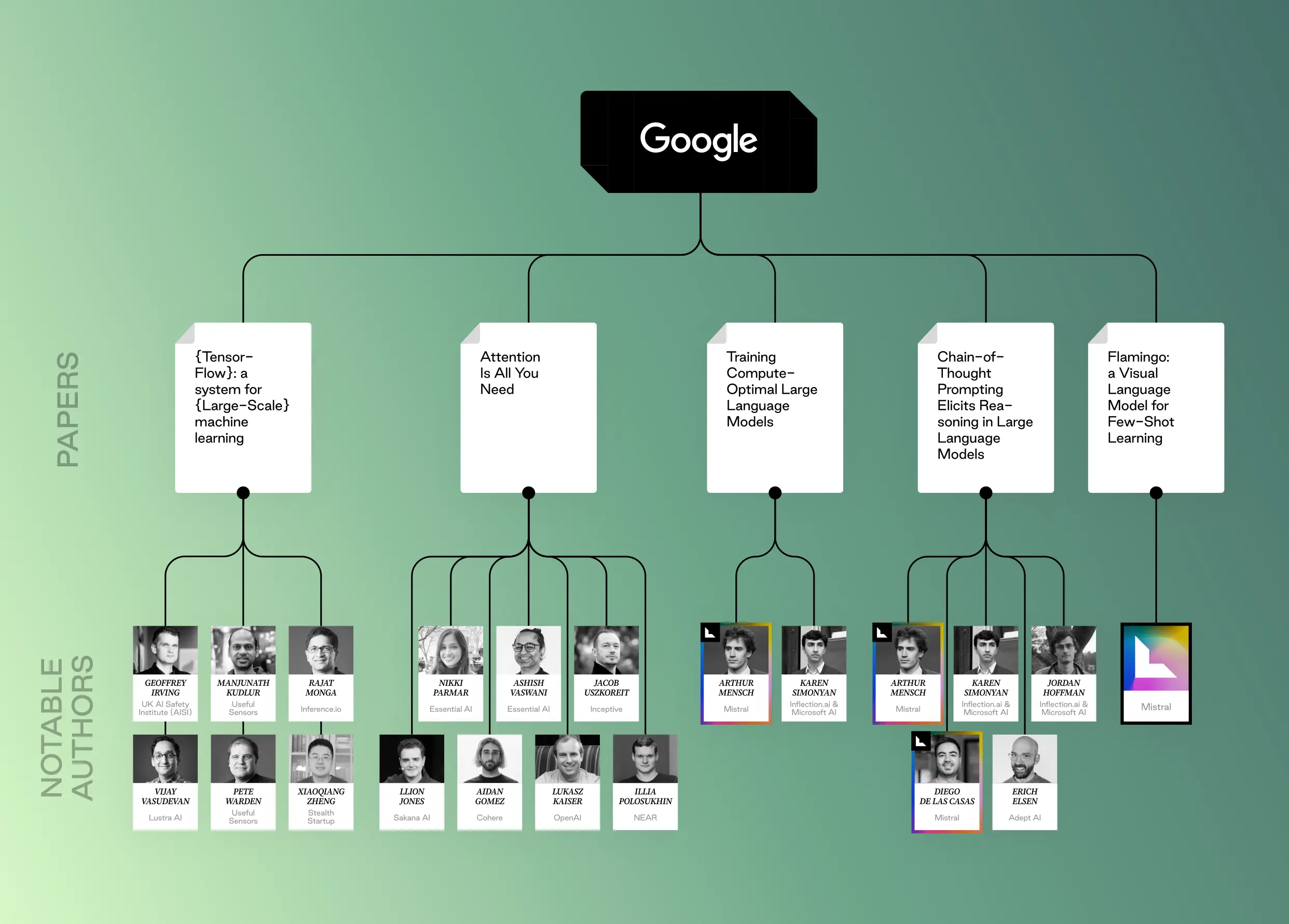
TensorFlow: A system for large-scale machine learning (2016), Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, Manjunath Kudlur, Josh Levenberg, Rajat Monga, Sherry Moore, Derek G Murray, Benoit Steiner, Paul Tucker, Vijay Vasudevan, Pete Warden, Martin Wicke, Yuan Yu, Xiaoqiang Zheng
TensorFlow has had a significant impact on developer productivity in machine learning. It simplifies the development process and reduces the time it takes to build and experiment with models by allowing developers to define machine learning models without needing to write low-level code for numerical computations.
In addition, TensorFlow can be deployed on various hardware platforms, including CPUs, GPUs, and TPUs (Tensor Processing Units). This flexibility allows developers to choose the best hardware for their specific needs and efficiently train large models.
-
Attention Is All You Need (2017), Ashish Vaswani, Noam Shazeer, Niki Parmar, Jacob Uszkoreit, Lilon Jones, Aidan Gomez, Lukasz Kaiser
The Transformer was a significant breakthrough in model architecture. Prior to this paper, most sequence transduction models relied on recurrent neural networks (RNNs) or convolutional neural networks (CNNs) to capture relationships between elements in a sequence. RNNs in particular can be slow to train due to their sequential nature.
This paper proposed a new architecture, the Transformer, that solely relies on an attention mechanism called “self-attention.” This allows the model to directly focus on relevant parts of the input sequence, leading to a better understanding of long-range dependencies. The Transformer architecture has led to faster training by removing RNNs, superior performance on machine translation tasks, and broad applicability to tasks like text summarization, question answering, and text generation.
-
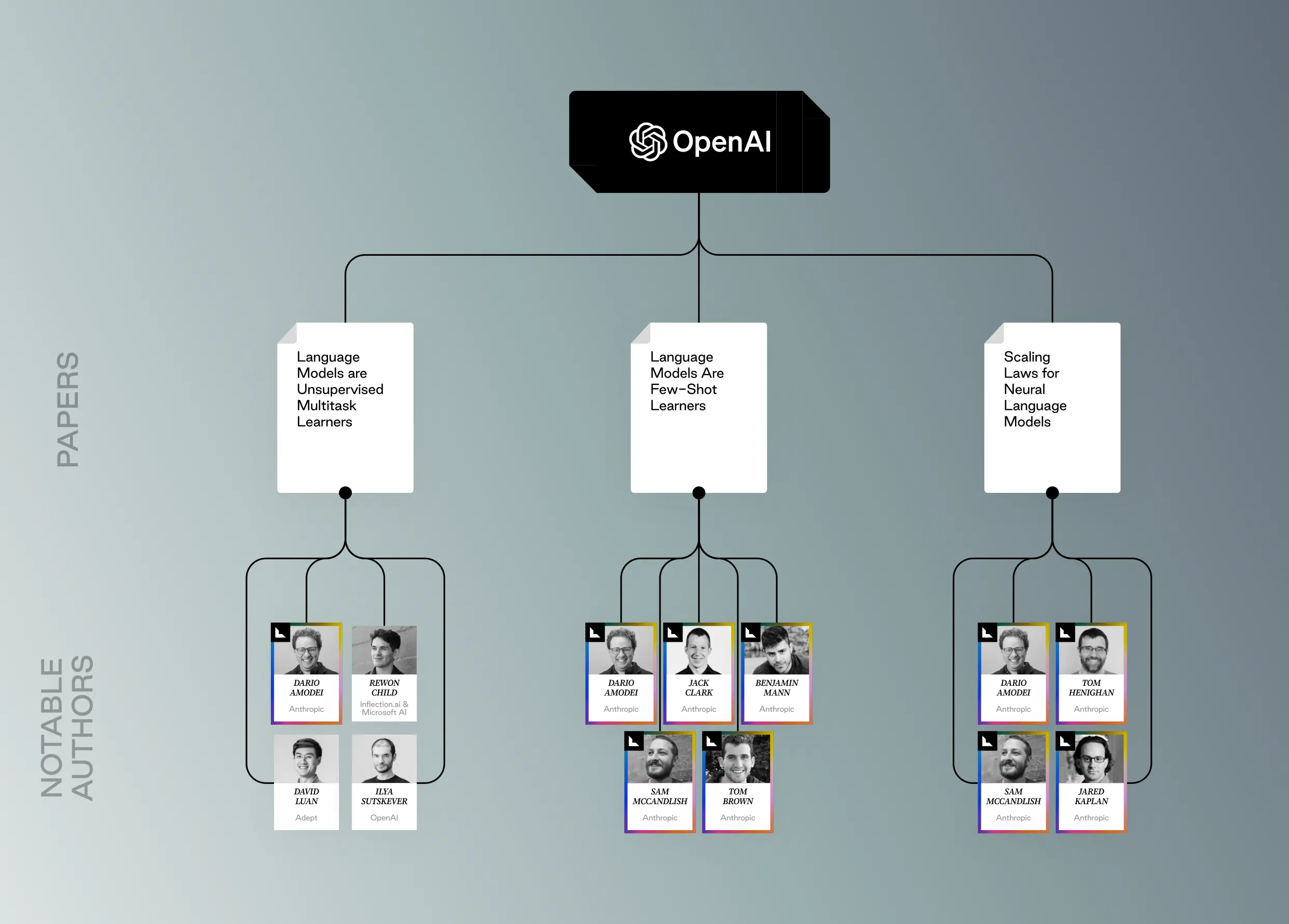
Language Models are Unsupervised Multitask Learners (2019), Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever
In the past, training LLMs involved supervised learning, requiring large amounts of labeled data specific to the desired task. This paper explored the potential of unsupervised learning, where the model learns from vast amounts of unlabeled text data.
By training on massive amounts of unlabeled text data, LLMs can inherently learn to perform various tasks (multitask learning) without explicit task-specific supervision. This unsupervised learning allows the model to capture general language understanding and capabilities that can be applied to various downstream tasks. Unsupervised learning also improves efficiency – LLMs can potentially learn from smaller amounts of labeled data when fine-tuned for specific tasks.
-
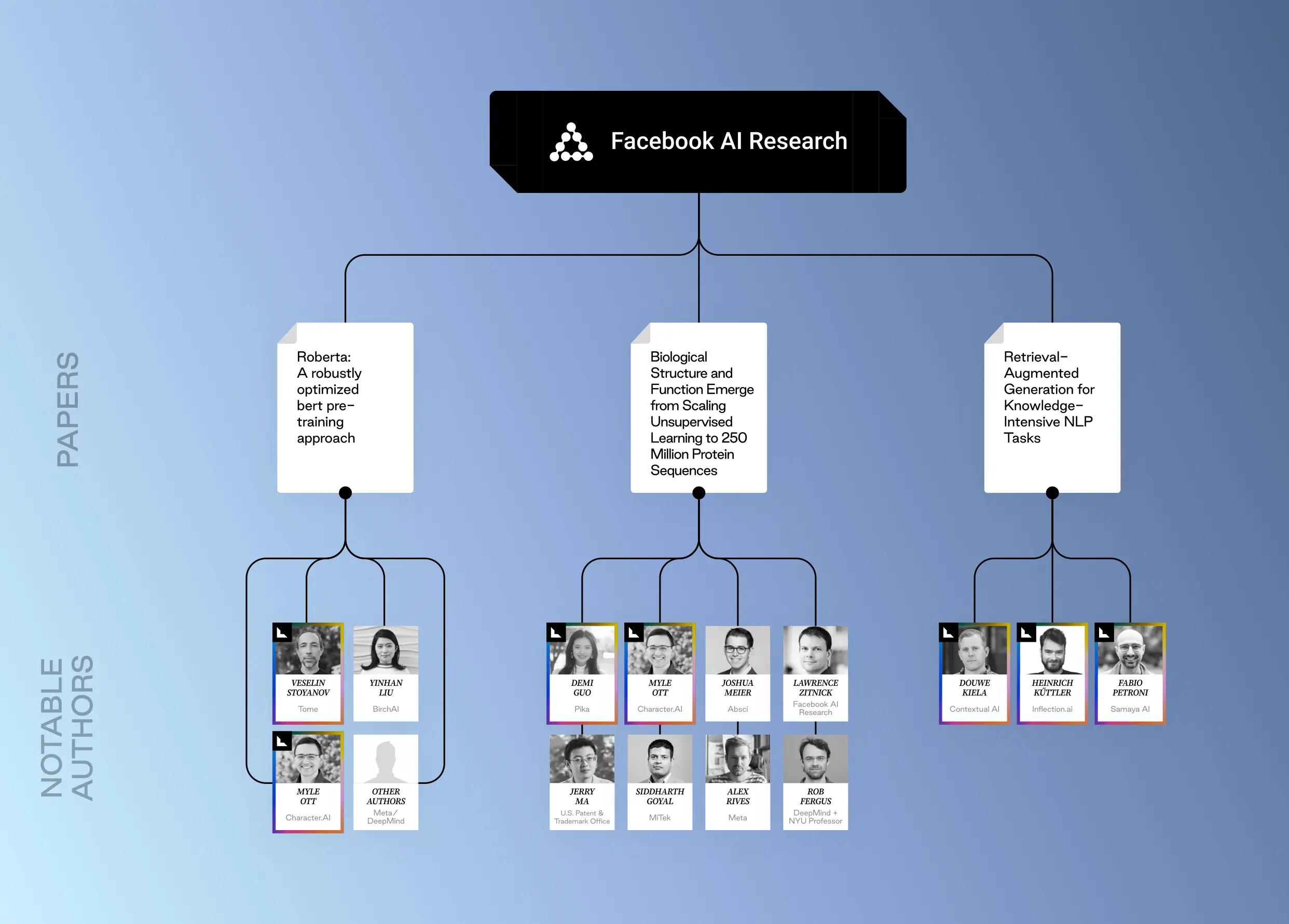
Roberta: A robustly optimized bert pretraining approach (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov
The paper focuses on improvements to the BERT (Bidirectional Encoder Representations from Transformers) pre-training process, leading to generally better performance on various NLP tasks and faster training convergence compared to BERT – allowing developers to iterate on models more quickly and spend less time. This translates to reduced training times, allowing developers to iterate on models more quickly and spend less time on hyperparameter during the fine-tuning stage. Though less transformative and famous than its predecessor paper, the Roberta paper is unique in that several co-authors have gone on to grow the AI ecosystem by founding or leading new startups, including execs at Tome, Character.ai and Birch.ai.
-
Biological Structure and Function Emerge from Scaling Unsupervised Learning to 250 Million Protein Sequences (2019) Alexander Rives, Siddharth Goyal, Joshua Meier, Demi Guo, Myle Ott, C Lawrence Zitnick, Jerry Ma, Rob Fergus
Traditionally, analyzing protein structure and function relied on techniques requiring labeled data (e.g., experimentally determined structures). This paper explores using unsupervised learning on a massive dataset of protein sequences (250 million) to learn inherent properties of proteins. By training a deep learning model on this vast amount of unlabeled sequence data, the model can learn representations that capture important biological information about proteins. This includes aspects like secondary structure, inter-residue contacts, and even potential biological activity.
RECENT ADVANCEMENTS
After 2020, the speed of AI development and adoption accelerated.
Recent AI research has made significant advancements in learning and processing, making technology more efficient and scalable to a wider set of applications. We’ve also seen the development of AI solutions to real world applications, startups built off of early models flourish, and startups built off of newer models emerge.
-
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (2020) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela
LLMs are trained on massive amounts of text data, but often struggle with tasks that require accessing and reasoning about specific factual knowledge. This paper proposes a new model architecture called Retrieval-Augmented Generation (RAG). RAG combines two key components – retrieval, a module that retrieves relevant documents from an external knowledge base based on the input prompt or question, and generation, a powerful LLM that uses the retrieved documents along with its own knowledge to generate a response.
This dual-memory architecture has led to improved performance on knowledge-intensive tasks (question answering, summarizing factual topics) and more precise and factual language. RAG offers a solution to the limited knowledge access issue of LLMs. It demonstrates that by combining powerful language models with external knowledge sources, we can achieve better results on knowledge-intensive tasks.
-
Transformers: State-of-the-art natural language processing (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick Von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, Alexander M Rush
Hugging Face Transformers is a popular open-source library built upon the foundation of the Transformer architecture. It provides access to a vast collection of pre-trained Transformer models for various NLP tasks, and offers a user-friendly API that allows developers to focus on fine-tuning models for their specific needs rather than training massive models from scratch, saving significant time and resources.
-
Language Models Are Few-Shot Learners (2020) Amanda Askell, Tom Henighan, Jack Clark, Benjamin Mann, Dario Amodei, Sam McCandlish, Tom Brown, Pranav Shyam, Rewon Child, Aditya Ramesh, Arvind Neelakantan, Christopher Burner, Christopher Hesse, Clemens Winter, Girish Sastry, Gretchen Krueger, Jeffrey Wu, Mark Chen, Matusz Litwin, Nick Ryder, Prafulla Dhariwal, Sanhini Agarwal, Scott Gray, Ilya Sutskever
This paper demonstrates that LLMs can learn new tasks with just a few examples (few-shot learning), making them more adaptable to various tasks where obtaining large amounts of labeled data might be expensive or difficult. This challenges the traditional view that LLMs always require vast amounts of data for good performance, and highlights the few-shot learning capabilities of LLMs – improved sample efficiency, meaning fine-tuning with just a few examples can lead to surprisingly good performance on new tasks, and faster model deployment, meaning that models can be rapidly adapted even in scenarios where labeled data is scarce.
-
Scaling Laws for Neural Language Models (2020) Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, Dario Amodei
By quantifying the relationship between model size, data size, computer, and performance, this paper offers a significant breakthrough in understanding how to optimize compute resources for training large language models (LLMs).
By understanding these scaling laws, researchers and developers can make informed decisions about how to allocate computational resources for LLM training.
-
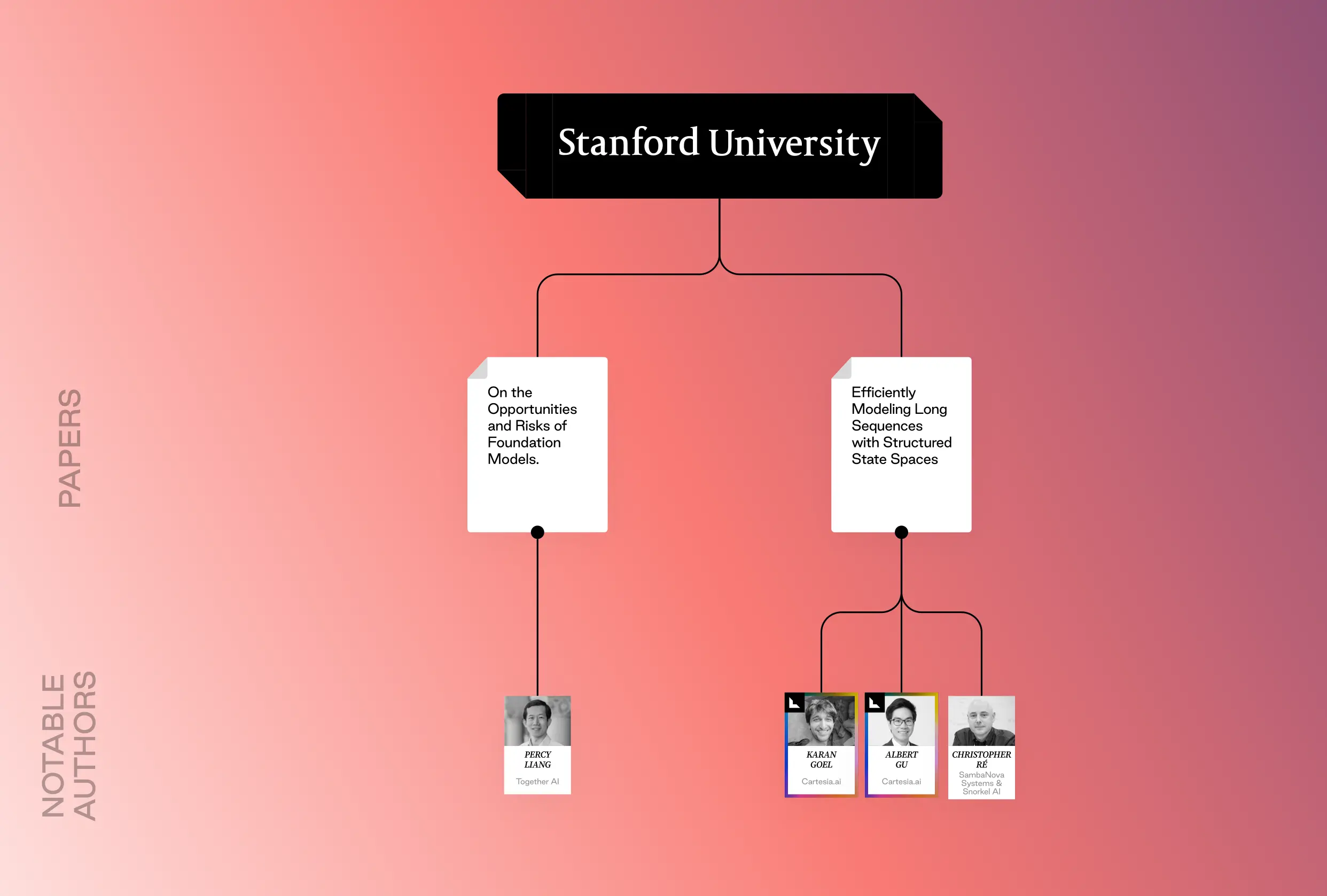
Efficiently Modeling Long Sequences with Structured State Spaces (2021) Albert Gu, Karan Goel, Christopher Ré
Often abbreviated as S4, this paper proposes a novel approach to handling long sequences by leveraging State Space Models (SSMs). RNNs and CNNS struggle to capture long-range dependencies in very long sequences (thousands of elements or more). S4 tackles this by using SSMs, which have the theoretical capability to handle long-range dependencies more effectively.
S4 also introduces a new parameterization technique called “structured state spaces” that offers a way to leverage the strengths of SSMs for long-range dependencies while maintaining computational efficiency. This opens doors for building models that can effectively handle very long sequences while being faster to train and use compared to traditional approaches.
-
Flamingo: a Visual Language Model for Few-Shot Learning (2022) Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, Karen Simonyan
This paper introduces Flamingo, a visual language model (VLM) specifically designed for few-shot learning in VLP tasks. While previous research focused on language-only or vision-only few-shot learning, Flamingo specifically tackles the challenge in the combined VLP domain. Flamingo leverages pre-trained models for image understanding and language generation, reducing the amount of data it needs for fine-tuning.
-
Training Compute-Optimal Large Language Models (2022) Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W Rae, Oriol Vinyals, Laurent Sifre
This paper investigates the idea of an optimal compute budget for training LLMs, arguing that current models are often undertrained due to a focus on scaling model size while keeping the amount of training data constant – and for optimal compute usage, the model size and the amount of training data should be scaled proportionally. The paper introduces Chinchilla, a large language model trained with this optimal compute approach.
-
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (2023) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, Denny Zhou
Typically, LLMs can produce seemingly correct answers without revealing the reasoning process behind them, but chain-of-thought prompting significantly improves how large language models (LLMs) perform reasoning tasks, incorporating examples of reasoning steps into the prompts used to instruct the LLM, guiding it to explicitly show its reasoning process, step-by-step, while solving a problem. LLMs trained with this technique demonstrate better performance on reasoning tasks like math word problems, answering common-sense questions, and performing symbolic manipulations.
-
Llama: Open and efficient foundation language models (2023) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample
The paper introduces the LLaMA family of federated learning models (FLMs) trained with a focus on efficiency. These models achieve state-of-the-art performance on various NLP tasks while requiring less computational power compared to previous models, translating to faster training times and reduced training costs. LLaMA models can potentially achieve good performance on NLP tasks even with smaller amounts of fine-tuning data, beneficial for those working with limited datasets or who need to quickly adapt models for new tasks. The LLaMA models also allow developers to leverage pre-trained components for various tasks – reducing the need to build models from scratch and promoting code reuse, saving development time and effort.
-
Legged locomotion in challenging terrains using egocentric vision (2023) Ananye Agarwal, Ashish Kumar, Jitendra Malik, Deepak Pathak
Navigating uneven and complex terrain is a critical challenge in robot locomotion. Typically, legged robots rely on pre-built maps or complex depth sensors to navigate their surroundings, limiting their ability to adapt to unforeseen obstacles and requiring significant computational resources. This paper’s novel approach sees the robot use a single front-facing depth camera (egocentric vision) to perceive its surroundings and plan its movements in real time, eliminating the need for pre-built maps and reduces reliance on bulky sensors.
By relying on egocentric vision, the robot can react to unseen obstacles and navigate challenging terrains like stairs, curbs, and uneven surfaces, making the robot’s movement more robust and adaptable to real-world environments.
-
Multimodal Foundation Models: From Specialists to General-Purpose Assistants (2023) Chenyu Wang, Weixin Luo, Qianyu Chen, Haonan Mai, Jindi Guo, Sixun Dong, Xiaohua (Michael) Xuan, Zhengxin Li, Lin Ma, Shenghua Gao
The development of multimodal foundation models that can handle various tasks across different modalities (like vision and language) is a significant shift from traditional models focused on a single data type (e.g., image classification models only processing images). Multimodal foundation models achieve better performance on complex tasks, and this research paves the way for developing AI systems that can interact with the world in a more natural and versatile way, similar to how humans use various senses to understand and respond to their surroundings.
CONCLUSION
LOOKING AHEAD
LIGHTSPEED’S VIEW ON FUTURE OF AI RESEARCH AND INNOVATION
Over the next 5–10 years, nascent forms of AI are poised to make transformative leaps across various domains. There are a few particular parts of the research landscape we are watching closely for breakthroughs that will lead to the next era of cutting-edge AI technologies.
ROBOTICS
Today, engineers are still working through basic issues around embodied AI. Current challenges include understanding data from multiple sensors, ensuring robots are adaptable to different contexts and settings, and working towards reasoning capabilities that could imbue robots with a degree of “common sense.” As AI research in robotics advances, breakthroughs in autonomous systems will enable more sophisticated and adaptable robots capable of navigating complex environments and performing a broader range of tasks. This is particularly important for industries like agriculture, where autonomous robots can revolutionize crop monitoring, harvesting, and precision farming, leading to increased efficiency and reduced labor costs. The same holds true in manufacturing, where advanced robotics has the potential to enhance existing automation, leading to safer and more efficient production processes.
AI AGENTS
Generative AI made waves for its ability to generate outputs based on user prompts, but many of the most pronounced and groundbreaking paradigm shifts will occur when AI begins doing work for us. In addition to simply querying AI for vacation ideas, we’ll be able to ask it to book the trip.
We already have early examples of agentive style AI in Github’s Copilot and other ‘AI assistants’, but to date, agentive technology has been limited to niche use cases with limited enterprise impact. As chain-of-thought reasoning capabilities improve and AI develops the ability to logic its way through a more generalized and complex set of tasks, the potential impact for businesses in every industry is vast.
AI INTERPRETABILITY
One of the biggest challenges with AI today is the ‘black box’ phenomenon – a lack of clarity on provenance in decision-making – which creates inherent distrust in outcomes. Improved interpretability techniques – understanding what models are ‘thinking’ about – or will allow users to gain deeper insights into AI decision-making processes, fostering wider adoption and ethical use of AI technologies.
This is particularly important in sensitive areas like finance and healthcare, where transparency is essential for regulatory compliance and maintaining user trust. Enhanced interpretability will ensure AI systems are more accountable and aligned with human values, promoting their safe and effective deployment across various industries.
VERTICALIZED APPLICATIONS OF AI
Verticalized applications of AI will increasingly streamline industry-specific workflows and transform the economics behind traditional engagement models for products— automating time-consuming tasks and reducing costs to free up humans to think bigger. We’re already seeing AI-driven contract analysis and research streamline and increase accuracy in the legal profession, while in healthcare, advancements in image recognition will revolutionize diagnostics, enabling radiologists and oncologists to detect diseases earlier and with greater accuracy, ultimately improving patient outcomes.
GET IN TOUCH
If you are a researcher exploring where and what to build in AI, a founder building on prior research, or we omitted an excellent piece of AI research from this roundup – we’d love to hear from you.
Get in touch with our team at generativeai@lsvp.com.

