
Could AI play an even bigger role in gaming & interactive media in the future?
This article was written in partnership between Lightspeed and Naavik.
At Lightspeed, with firmwide conviction, we continue our thesis of AI as an unprecedented source of value creation—reshaping industries even faster than the platform and architecture shifts we observed during the emergence of the internet, mobile phones, and cloud computing.
To date, we have invested ~$2.5 billion in over 100 companies in the AI technology stack. These portfolio companies offer products ranging from foundation models to AI-native developer tooling and applications in enterprise, healthcare, financial technology, consumer, and gaming & interactive media.

Today’s generative media modalities: text, audio, images, and video
As an increasing share of our time is spent online and interacting with digital content, AI’s impact on gaming & interactive media has shaped not only Lightspeed’s investment approach (backing category-defining companies, including Inworld in AI character development, Pika in AI video generation, and Suno in AI music creation), but also profoundly impacted how consumers play, work, and connect.
While we are still relatively early days in terms of the development and consumer adoption of AI applications, we have already seen foundation models drive significant economic value across modalities, including:
- Text (e.g., OpenAI ChatGPT, Anthropic Claude, xAI Grok, etc.),
- Audio & music (e.g., Suno, ElevenLabs, etc.),
- 2D Images (e.g., OpenAI DALL·E 3, FLUX.1, Stable Diffusion 3.5, Ideogram, Midjourney, etc.), and most recently,
- 2D Videos (e.g., Pika 2.0, Sora, Runway Gen-3 Alpha, Luma Photon, Google DeepMind Veo 2, etc.)—also considered “3D” (2D + time).
These fundamental innovations have democratized content creation for consumers, creators, hobbyists, and prosumers, allowing them to design and deliver novel content consumption experiences previously accessible only to trained professionals.
Across each of these modalities, the models have become not linearly but rather exponentially more powerful with each generation. Taking text as an example, GPT-3 to GPT-4 saw remarkable deltas in model size (175B parameters to 1.8T parameters), context window (2048 tokens to 128k tokens), and ultimately reasoning capability (bottom 10% of test-takers vs. top 10% of test-takers). And the pace of progress has also accelerated: since the release of GPT-4 in March 2023, OpenAI has released GPT-4 Turbo (November 2023), delivering a far larger context window, GPT-4o (May 2024) delivering the first truly multimodal LLM twice as fast and half the cost of Turbo from ~6 months prior, GPT-4o Mini (July 2024) with even lower API costs, o1 (September 2024) with advanced reasoning capabilities, and o3 (December 2024) setting benchmarks across coding, mathematics, and science.
Tomorrow’s expansion: generative games
What comes after generative videos? Many consider world models the next major “modality” in AI.
In machine learning terms, a world model can imagine how a virtual (or physical) world evolves in response to an agent’s (for example, a player’s) behavior. Building on advancements in video generation and autonomous vehicles, these “world simulators” can deliver three-dimensional and interactive experiences with temporal and spatial consistency—also considered “4D” (3D + time).
For simplified purposes, we will think of world models as generative or “engine-less” video games: virtual worlds that allow user input and respond coherently and in real time.
While world models are still the earliest in development and output fidelity, they already demonstrate various emergent capabilities at scale, including complex character animation, physics, agent action prediction, and object interactivity. World models are trained on large datasets across all other modalities (text, audio, images, and videos) to ultimately develop the ability to reason about the consequences of actions.
The implications of world models will be far-reaching, not only for virtual worlds. Meta’s Chief AI Scientist Yann LeCun described in a recent talk how world models would eventually “understand the (physical) world” and possess the ability to “reason and plan to the same level as humans,” serving as the foundation for complex task execution across consumer (e.g., clean my room, wash my dishes, take my dog on a walk) and commercial (e.g., full industrial robotics) environments that current modalities are not capable of. Many of the nearest-term applications of world models, however, we do expect will be the on-demand generation of gaming & interactive media applications (2D and 3D-style output) or live-interactive video experiences (2D-style output).
Several key questions remain, including the massive amounts of data and computing power required to train and run world models, as well as how to deal with hallucination and model biases. But if there are lessons to be drawn from advances in previous modalities–it’s that things often start a bit wonky but look extremely compelling only a few years later. Before we get into our views on the future impact and potential applications, let’s start with a brief history of how we got here.
A brief history of world models in gaming (2018–2023)
AI world models are gearing up to fundamentally reshape game development, driving innovations in how virtual environments are created, understood, and interacted with. This journey—from foundational breakthroughs to cutting-edge applications—shows a series of rapid advancements, each building on the successes of its predecessors. In the same way, AIs have become better at understanding and playing games, and they are now rapidly improving at visualizing and creating complex, interactive 3D worlds.
Let’s look at the timeline of developments that led to where we are today.
2018: Ha and Schmidhuber’s world models
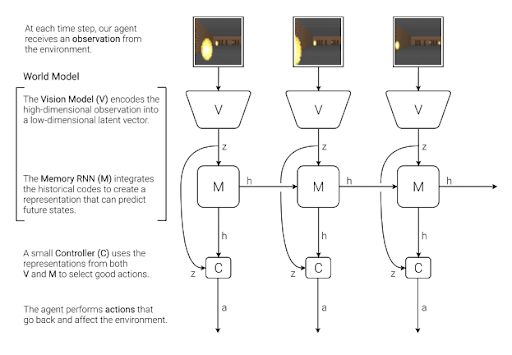
Imagine an AI learning to navigate game worlds by visualizing them in its mind, much like a player picturing the layout of a maze before stepping into it. This was the essence of David Ha and Jürgen Schmidhuber’s academic paper, “World Models.” Their framework combined Variational Autoencoders (VAEs) to compress visuals into essential abstractions, Recurrent Neural Networks (RNNs) to predict how these abstractions might change over time, and a controller to decide the best actions. For instance, the model mastered the game CarRacing-v0 by simulating laps internally, optimizing strategies without direct interaction. This breakthrough showed that AI could solve tasks by imagining a game world, much like mentally rehearsing moves in Chess. By enabling efficient decision-making through abstracted representations, this architectural innovation laid the groundwork for future advancements.
2019: PlaNet and latent dynamics
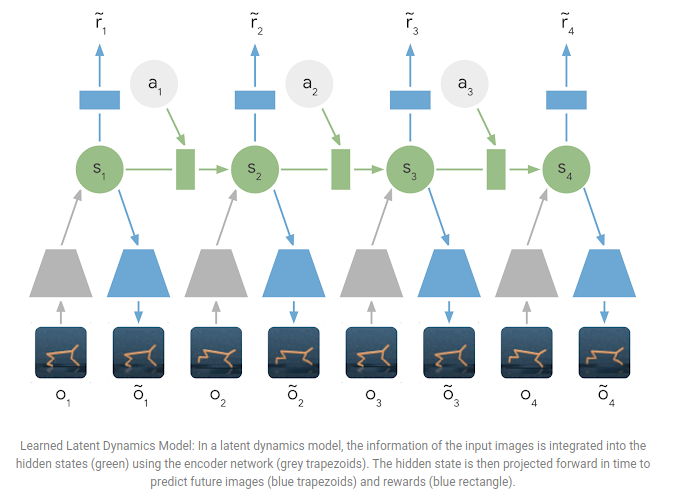
While Ha and Schmidhuber enabled AI to imagine game worlds, Danijar Hafner’s Deep Planning Network (PlaNet) gave it the tools to sketch detailed blueprints. PlaNet refined model detail abilities with “latent dynamics,” a process akin to summarizing an entire city map into key landmarks to navigate efficiently. These simplified abstractions of the environment allowed PlaNet to plan actions by simulating outcomes in this condensed representation rather than relying on raw, complex data.
This innovation made PlaNet a natural strategist in games requiring continuous control, such as robotic locomotion or avoiding ghosts in a virtual Pac-Man. By focusing on the big picture, PlaNet demonstrated that abstract sketches of environments could lead to smarter, faster decision-making—a significant leap toward generalizable AI planning.
2020: Dreamer and learning through imagination
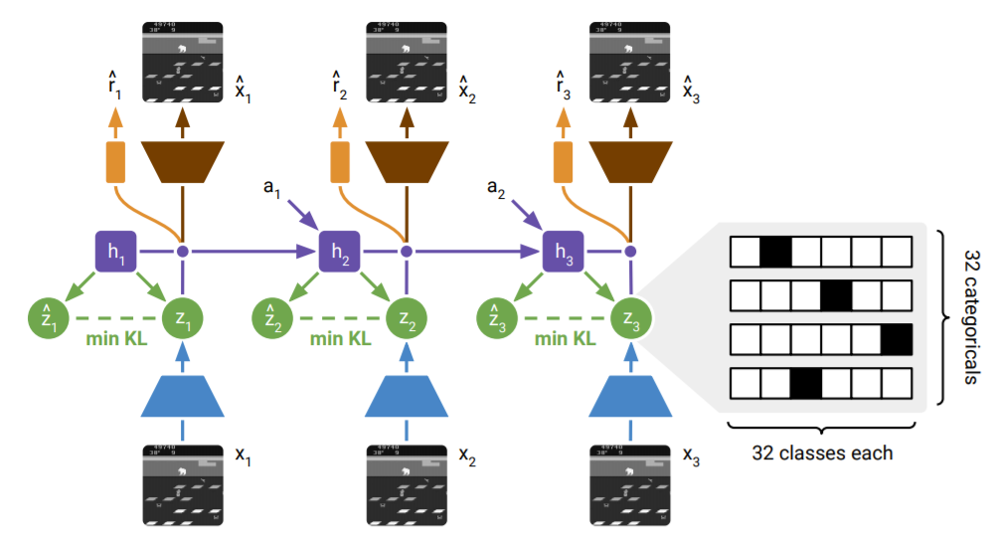
Dreamer elevated the idea of imagining as the AI moved from sketching to playing out full “dreams” of possible futures. Dreamer integrated PlaNet’s latent dynamics with reinforcement learning, enabling it to simulate detailed trajectories and refine policies based on imagined scenarios.
Like a player envisioning the ripple effects of their choices in a strategy game, Dreamer’s ability to simulate future scenarios in its latent space enabled it to refine strategies without trial-and-erroring in the real game. For example, Dreamer excelled at tasks like guiding a robot arm and navigating virtual landscapes by vividly playing out its dream moves internally. DreamerV2 expanded this capability to more complex Atari 2600 games, acting as a benchmark to evaluate imaginative prediction and agent performance. This helped prove that detailed simulations often trump brute-force experimentation.
2023: Runway’s general world models and DeepMind’s Genie

In 2023, Runway, one of the leaders in AI video generation, announced its General World Models plans, which aim to use generative adversarial networks (GANs) and advanced spatial modeling to generate simulations of 3D worlds. Some progress has been made with Runway’s demonstration of a 3D camera system for its video generation, but interactivity was still severely limited.
During the same period, DeepMind’s Genie (within Alphabet) took the technology up another level. When users provide an image as a prompt, Genie conjures interactive 2D worlds, complete with real-time physics and spatial memory. To get technical for a moment, Genie uses what’s called a spatiotemporal video tokenizer, a type of autoregressive dynamics model, and a scalable latent action model to enable frame-by-frame interactivity without requiring labeled action data for training. Put more simply, imagine describing a “haunted castle with secret passages” and instantly having a fully playable level without requiring special domain or genre knowledge, despite being trained on publicly available videos of 2D platformers. For the first time, the idea of “world models” was finally starting to live up to its name.
Status quo: a tipping point (2024–2025)
2024: DeepMind’s Genie 2
In 2024, the pace of innovation accelerated dramatically, marking a tipping point where AI world models are beginning to transition from experimental R&D to practical tools for game developers. Generative 3D, interactive worlds are now coming to life via a wider host of new and old contenders.

Built on its predecessor, Deepmind’s Genie 2 introduced finer-grained environmental interactions and expanded multimodal inputs. It also made the leap to 3D environments with more robust physics and animations including first-person, third-person, and even vehicle-based games like driving and sailing. This version also enables more dynamic interactivity, such as bursting balloons, exploding barrels, and climbing ladders.
Deepmind has provided a number of different demonstrations, but the model isn’t publicly accessible and lacks stability beyond one minute of interactivity. A big improvement on the world model aspect is its “long horizon memory,” which allows for remembering parts of scenes to be rendered accurately again as they leave and return to view.
2024: GameNGen
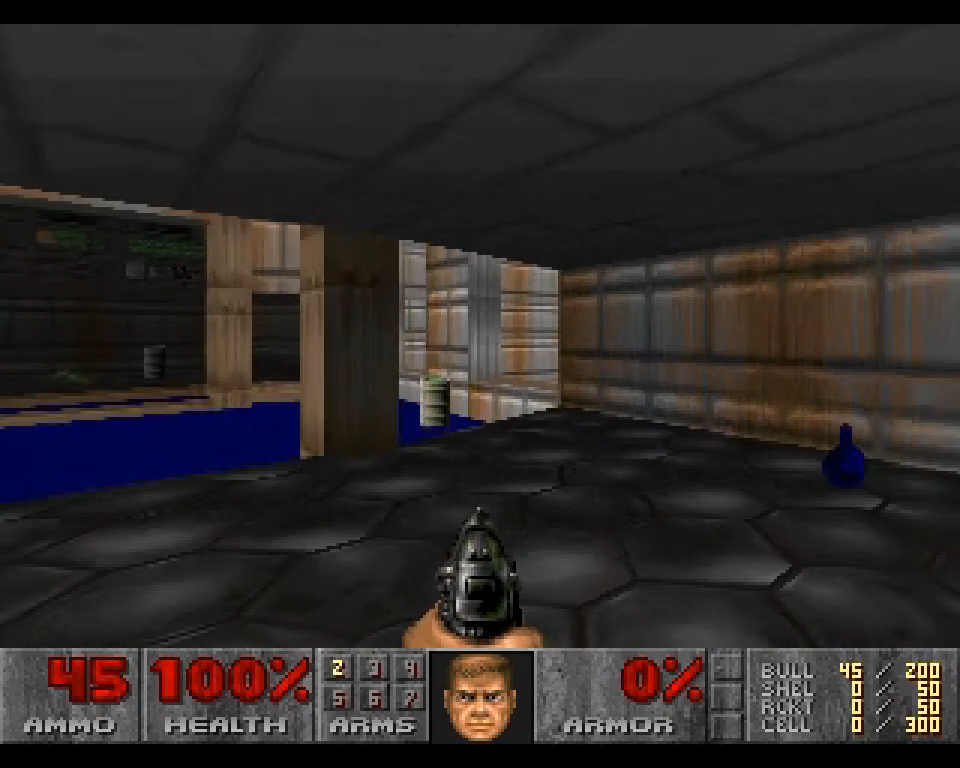
Another interesting breakthrough is GameNGen (from another research team at Google), which uses a neural game engine that acts as a “living” development platform, adapting game elements in real time. The system was demonstrated by simulating the classic game Doom at over 20 FPS, generating an endlessly expanding environment as the player goes through it.
GameNgen uses a combination of reinforcement learning (via an AI agent collecting data by playing the game) and the training of a generative diffusion model for rendering the environment. More specifically, the diffusion model is built on Stable Diffusion 1.4, and is cleverly modified to replace the normal text prompts with the previous gameplay frames (combined with action inputs from the training agent). This way, the new frames generated are in sync with the previous gameplay frames and player actions.
2024: Tencent’s GameGen-O

Another tech giant and largest games company in the world, Tencent, is creating GameGen-O, which recently hinted at the future of large-scale content generation by targeting open-world games with a diffusion transformer model. Its Open-World Video Game Dataset (OGameData) is built on over one million diverse gameplay video clips with informative captions from GPT-4o. The model uses a two-step process of pre-training text-to-video and “InstructNet” control model training using game-related multi-modal control signal experts. The demonstrations currently only last a few seconds and, despite being visually impressive, aren’t in real-time at the moment. However, it’s worth keeping an eye on, given how Tencent would want its studios to have access to leading-edge technology.
2024: DIAMOND
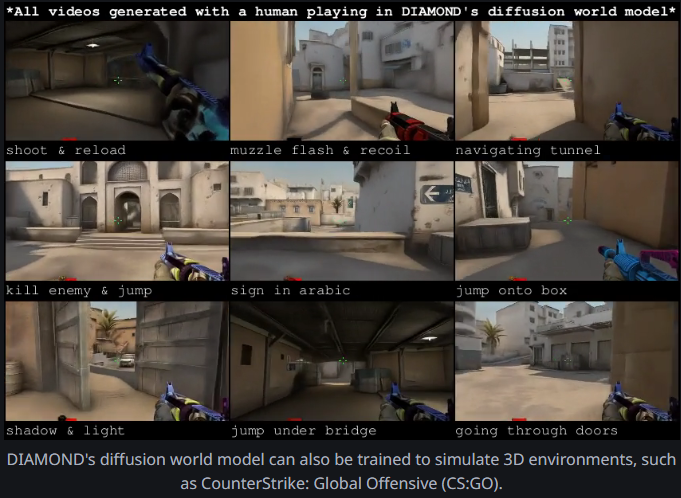
After a few years of R&D, AI models moved beyond playing games to creating them. Another academic model, DIAMOND (DIffusion As a Model Of eNvironment Dreams), entered the stage in 2022. DIAMOND used diffusion techniques, the same methodology used by popular image generators like Stable Diffusion and Midjourney, to iteratively refine images, acting like an artist painting hyper-realistic backdrops for game worlds. This allowed DIAMOND to predict and generate high-fidelity video simulations, including a playable simulated CS:GO environment.
This model’s ability to create lifelike settings made it a game-changer for visually rich simulations, but not necessarily interactivity. Even so, the possibilities of how world models could one day play a role in game development became clearer.
DIAMOND’s 2024 paper was a NeurIPS 2024 Spotlight, making significant advances in training simulated 3D environments.
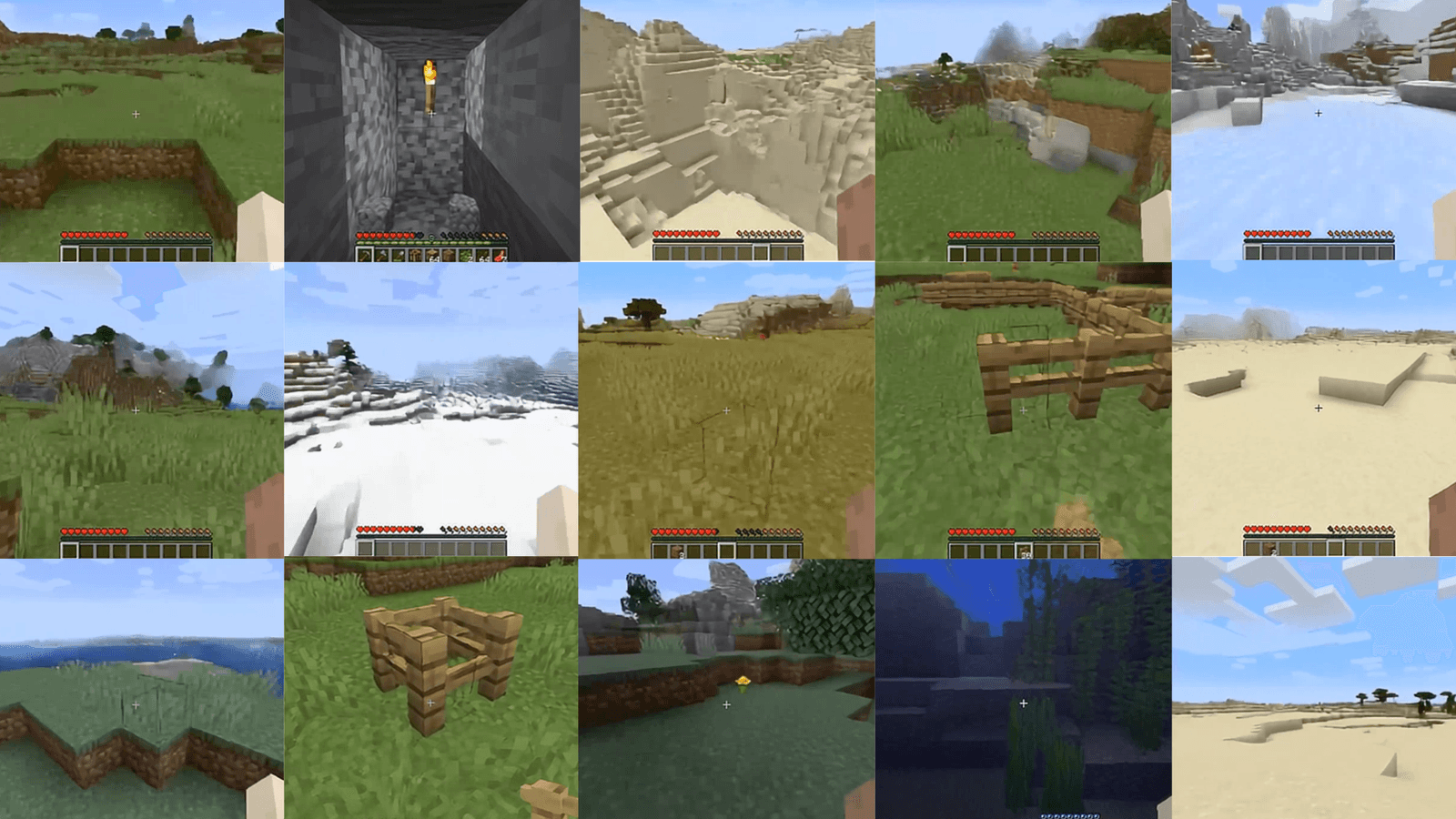
2024: Decart’s Oasis
In another example, Decart and Etched created Oasis as a technical demo of a Minecraft-like generative interactive world model. In a first for a publicly available demo, Oasis takes in user keyboard input and generates real-time, physics-based gameplay, allowing players to move, jump, pick up items, break blocks, and more. Its world model understands game elements like building, lighting, physics, and inventory management.
This model is built with a two-part system of a transformer-based spatial autoencoder and latent diffusion backbone. It was trained on open-source data from VPT, OpenAI’s M.I.T. license open-source Minecraft dataset. Like the Doom GameNgen demo mentioned above, this demo also runs at 20 FPS, but it also allows real-time player input and runs on a custom chip, Sohu.
Decart co-founders Dean Leitersdorf and Moshe Shalev also quoted breakthroughs in video inference based on custom low-level performance optimization of GPUs–allowing for cost-effective live-generation of interactive 2D and 3D content.
Shortly after their release, YC company Lucid showcased a similar Minecraft demo.
2024: World Labs
World Labs, founded by famed AI researcher Fei-Fei Li, also recently introduced tools for transforming 2D photographs into spatially coherent 3D environments. The environments demonstrated are rendered live in the browser with WASD/Mouse control and include features like depth of field camera effects, dolly zoom with FOV, and correct physical geometry. Unlike the frame-by-frame models, World Labs generates full 3D scenes simultaneously with stable persistence and real-time player controls. The 3D scene is generated with pixel depth maps to predict 3D geometry from an image and turn it into a world model that maintains physical consistency.

2025: Odyssey
Lastly, Odyssey’s Explorer system is similar to Oasis, but it’s tuned more for photorealistic scenes using Gaussian splats (rather than a Minecraft-like look) due to training on real-world 360 captures from a custom camera. Scenes created with Explorer don’t include real-time gameplay or mechanics. They are instead generating a scene from a text prompt that can be loaded into Unreal Engine, Blender, or After Effects for usage in games or media.
The team is drawing on their background in self-driving cars and drawing on proprietary 3D data collection as a competitive advantage for their models.

2025: Microsoft’s MUSE
Not to be outdone by startups, Microsoft unveiled its own world model that can be used to generate video game scenes and environments, which change in response to a game player’s actions on their game controller. Muse was trained by Microsoft researchers and staff in its Xbox gaming unit using seven years’ worth of gameplay footage from its Xbox game Bleeding Edge.
The company is positioning the technology not to replace but to enhance traditional game design. The model is meant to be a tool for game developers, and it could one day be used to speed up game development or create games customized to individual players. GameFile’s Stephen Totilo encapsulated the player and developer community’s mixed reception.
From a data perspective, it makes sense. Thanks to Microsoft’s Xbox ecosystem and acquisition of Activision, what YouTube is for Google’s Veo2, gaming videos coupled with human actions (e.g., keyboard or controller inputs) are for Microsoft.
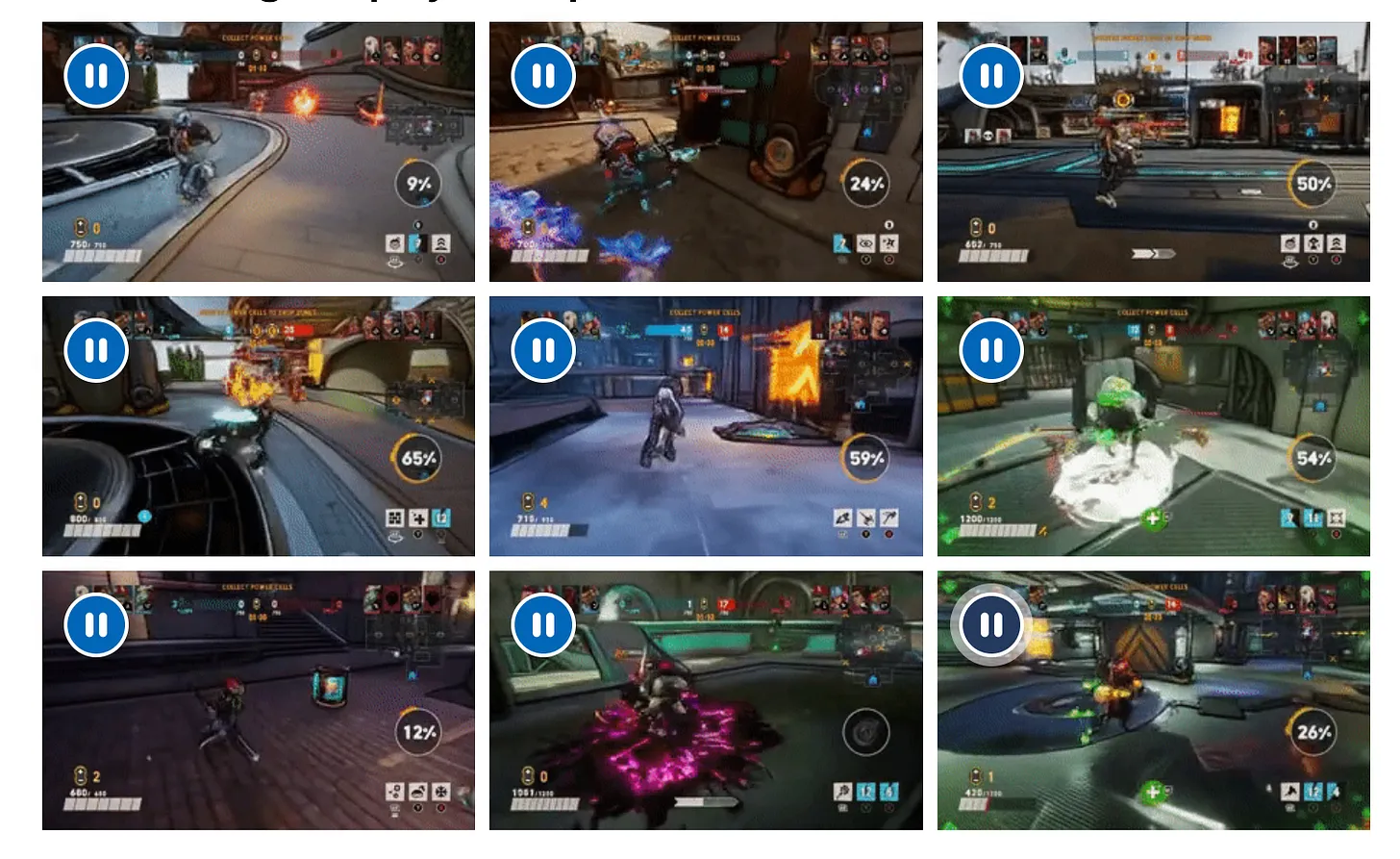
And to end with an honorary mention: OpenAI’s Sora video model can also render game-like experiences.
Future & predictions
Making assumptions about the technologies to come in a space as fast-moving as world models is not easy. As investors, seeing the present clearly is oftentimes more realistic than predicting the future–and a necessary ingredient unless you get it right by chance.
In this spirit, we sought out leading world-model startups and research labs to learn what’s on their mind. The following assumptions are repeating patterns in our conversations:
1) World models are likely not here to replace AAA video games any time soon—they will instead enable novel, “previously impossible experiences.”
The importance of applying AI in ways that drive genuine innovation was also a core thesis in our previous AI x gaming post released in mid-2023.
With technology making big strides quarterly, we believe predictions about winning approaches will come back to the basics of what has previously created great break-out companies during historically comparable paradigm shifts like the internet or mobile.
Efficiency and cost gains enabled by AI are interesting and important. But true breakouts will not simply retrofit or rationalize the creation of existing products; they will be built natively and from the ground up for completely novel and previously impossible experiences.
For world models, such experiences could be:
- Playing a book or photo (e.g., truly diving into your favorite text or a family memory)
- Live-direct a movie (i.e., modifying a movie as it plays, like a real-time version of Bandersnatch)
- Augment a selfie video or Zoom call with unlimited filters or style transfers (like Snap filters, except for not being limited to the “handcrafted” options)
These new experiences will be built by extraordinary founders who follow their instincts (often unfair, proprietary knowledge) into unique insights and ideas.
2) Statefulness and memory limitations will require incremental innovation to deliver long-term, engaging, and retaining worlds.
Most current world models generate highly detailed environments but lack persistent state modeling, a foundational element in traditional video games. Unlike “handcrafted” game engines that track player progress, inventory, and world changes over time, today’s world models generate new frames or scenes independently, without an underlying memory structure.
This limitation prevents them from supporting complex mechanics like progressive level changes, long-term cause-and-effect relationships, or non-linear storytelling. Without breakthroughs in stateful architectures, world models will remain better suited for dynamic simulations than true interactive game worlds.
3) As it relates to games, world models could be outdone by AI-automating “traditional” algorithm- and engine-based experiences.
This one is a bit trickier to wrap one’s head around, but especially as AI is also getting better at automating code production and generating 3D assets, automating the existing game design process (using a game engine such as Unreal Engine or Unity)—including the on-the-fly generation of relevant 3D assets and textures–could prove superior to probabilistic live video generation models.
Even hybrid experiments are run today:
- World models: 2D representation, predicting the next video frame based on user input.
- AI-automating traditional design: 3D representation, using code and assets to deliver stateful experiences.
- Blended approaches: Using “grey box” 3D representation for stateful modeling and spatial and temporal integrity and applying video models (like a style transfer) on top of it.
4) “Multiplayer world models” are around the corner.
Multiplayer world models present significant challenges but remain feasible with the right architectural approaches.
The core difficulty lies in maintaining consistent, synchronized world states across multiple players while leveraging generative models that are inherently probabilistic and dynamic. Unlike traditional multiplayer games, which operate on deterministic state updates, world models introduce variability that can lead to desynchronization and inconsistencies.
However, techniques like server-side authoritative models, hybrid approaches combining generative AI with deterministic physics, and efficient data streaming could mitigate these issues. We haven’t seen multiplayer world models in the wild. But we hear they aren’t far away.
5) Legal and copyright considerations are not trivial–and even more complicated.
As world models become increasingly sophisticated, they raise complex legal and ethical questions. Who owns the rights to procedurally generated assets? If a model trained on existing video games outputs something highly similar to a known IP, does that constitute copyright infringement?
For example, DeepMind’s Genie can generate interactive game levels based on video input, which raises concerns about derivative works. Similarly, GameGen-O and GameNgen, which synthesize playable experiences from text prompts, could unknowingly produce assets resembling those from existing franchises. Studios, publishers, and regulators will need to navigate a rapidly evolving legal landscape where traditional IP frameworks may no longer suffice.
Legality dimensions for ingested video game streams are even more layered and thus complicated: imagine a Twitch video of FIFA (now EA Sports FC): There’s FIFA, the game–as well as its player and team IPs. But also the streamer and (arguably artistic or athletic) act of playing and entertaining an audience. And there’s the input from the audience and chat itself. And the streaming platform that is providing the experience to its users.
6) Training convincing world models will require 3D data sets for spatial and temporal consistency.
Most generative AI models today are trained on predominantly 2D datasets, which limits their ability to maintain spatial and temporal consistency in fully realized 3D environments.
Games and simulations require a deep understanding of object permanence, occlusion, physics interactions, and long-term state changes–challenges that 2D-trained models struggle with. For instance, DeepMind’s Genie can generate interactive game scenes, but without a native 3D training dataset, it faces inconsistencies when rendering depth, object interactions, or persistent physics states. To achieve true spatial and temporal coherence, future world models will likely need large-scale 3D datasets, potentially sourced from real-world scans, synthetic environments, or high-fidelity game engines.
7) Simulation without playability won’t engage or retain users for long.
While world models excel at simulating environments, turning them into engaging, structured gameplay experiences remains a significant challenge. The ability to generate infinite landscapes or dynamic NPCs does not inherently lead to fun, balanced, or meaningful player experiences. A compelling game requires intentional level design, progression systems, and player agency–elements that pure procedural generation struggles to ensure. Odyssey, for example, can generate vast explorable worlds, but ensuring coherent mission structures or meaningful challenges within them still requires human intervention. Future advancements will likely involve hybrid approaches, where AI-generated worlds are guided by curated design principles.
8) Scalability and compute efficiency will continue to improve, likely not posing a long-term impediment to world models.
The cost of training and running large-scale world models remains a major barrier to widespread adoption, but improvements in AI efficiency are beginning to shift this landscape.
Over the last five years, generative models have become dramatically more cost-effective, with architectures optimized for lower power consumption and inference efficiency. Decart Oasis, for example, has pioneered new GPU-efficient techniques that reduce the compute requirements for real-time world generation. Meanwhile, advancements in quantization and model distillation are making it possible to run complex simulations on consumer hardware. As these trends continue, world models could become viable not just for large studios but also for independent developers and even real-time applications.
9) The most valuable near-term use cases for world models may lie outside games, e.g., in robotics.
Immediate use cases for world models extend well beyond traditional gaming environments. In robotics, for instance, they can power real-time interactive video models that dynamically understand and react to complex surroundings–paving the way for more intuitive and adaptive robotic systems.
Building something interesting in world models or at the intersection of gaming and AI?
Let’s chat! Founders chose Lightspeed as the #1 gaming lead investor of 2023 & 2024—and we’d love to explore a partnership with you! You can reach us at moritz@lsvp.com and faraz@lsvp.com.
This article was written in partnership with Naavik, a gaming-focused consulting and advisory firm that has helped 250+ clients make better games, businesses, and investments. Naavik also operates an industry-leading research hub, including Naavik Digest and the Naavik Gaming Podcast. To learn more and reach out, visit naavik.co.
The content here does not constitute an offer to sell or a solicitation of an offer to buy any securities or investment advisory services.
The views expressed are those of the authors and do not necessarily represent the views or opinions of Lightspeed. Other market participants could take different views. Unless otherwise indicated, the inclusion of any third-party firm and/or company names, brands and/or logos are for representational purposes and does not imply any affiliation with these firms or companies and also does not imply their endorsement of the views expressed by the authors.
Certain information contained herein is based on information from various sources prepared by third parties. While such sources are believed by Lightspeed to be reliable, neither Lightspeed nor its affiliates assume any responsibility for the accuracy or completeness of such information, and such information has not been independently verified by Lightspeed. For more details please see https://www.lsvp.com/legal.
Authors



